3 min to read
Reinforcement Learning : Q-Learning
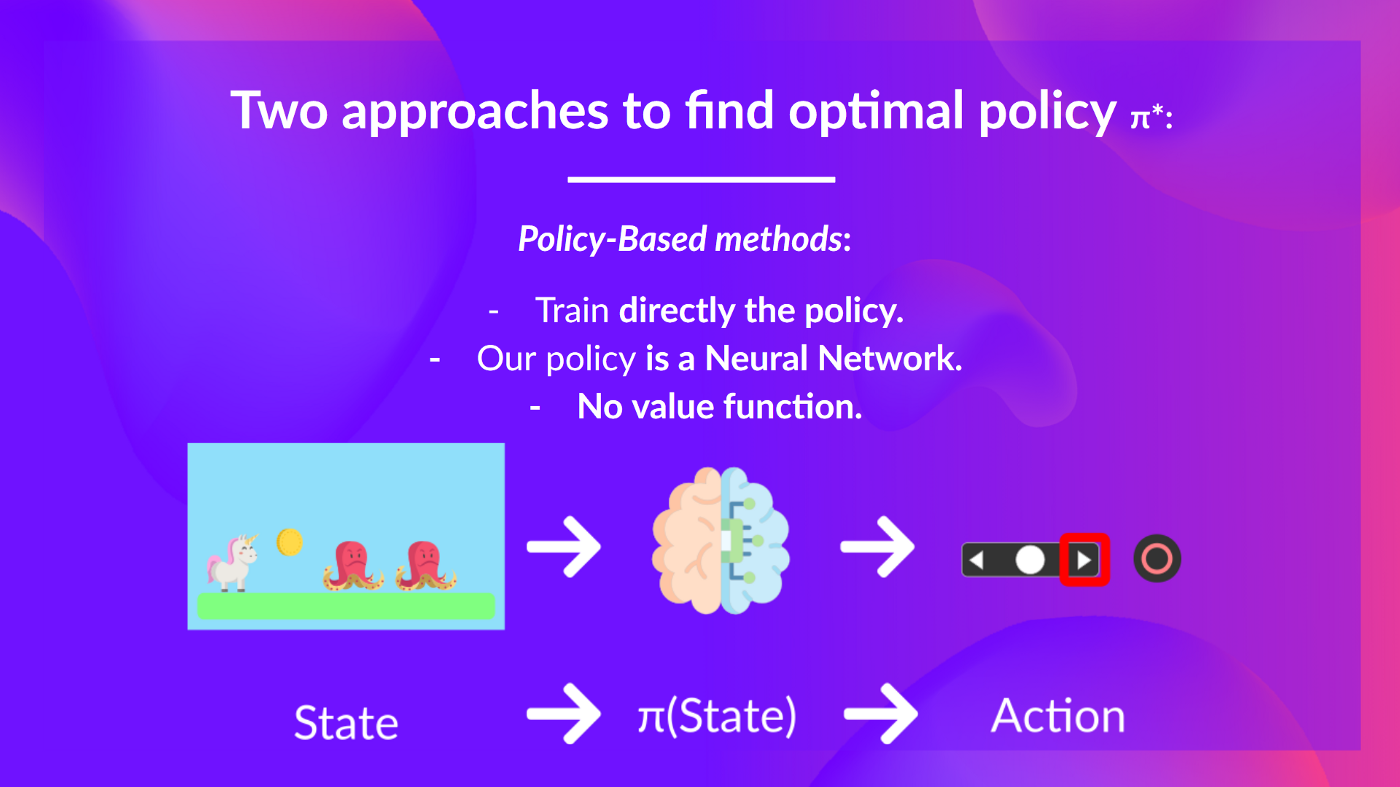
Policy-based methods: Directly train the policy to select what action to take given a state (or a probability distribution over actions at that state). In this case, we don’t have a value function.
Value-based methods: Train a value function to learn which state is more valuable and use this value function to take the action that leads to it.

Because we didn’t train our policy in value based methods, we need to specify its behaviour. For instance, if we want a policy that, given the value function, will take actions that always lead to the biggest reward, we’ll create a Greedy Policy.
We have Two types of Value-Based Functions:
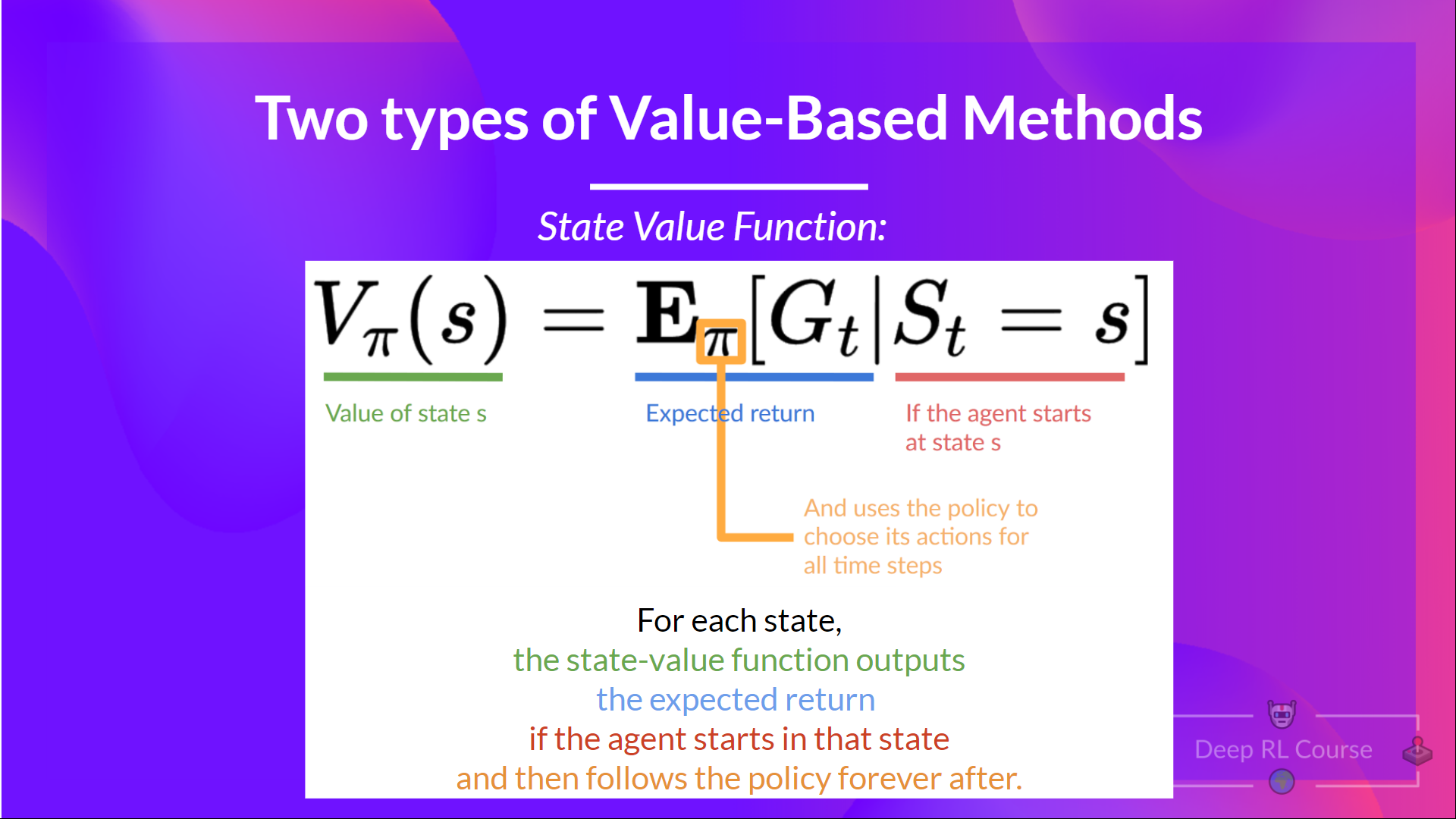
We see that the difference is:

- In state-value function, we calculate the value of a state S_tSt
- In action-value function, we calculate the value of the state-action pair (St,At ) hence the value of taking that action at that state.
**The Bellman Equation: simplify our value estimation**
The Bellman equation is a recursive equation that works like this: instead of starting for each state from the beginning and calculating the return, we can consider the value of any state as:

What is Q-Learning?
Q-Learning is an off-policy value-based method that uses a TD approach to train its action-value function:
- Value-based method: finds the optimal policy indirectly by training a value or action-value function that will tell us the value of each state or each state-action pair.
- Uses a TD approach: updates its action-value function at each step instead of at the end of the episode.
Q-Learning is the algorithm we use to train our Q-Function, an action-value function that determines the value of being at a particular state and taking a specific action at that state.
The Q comes from “the Quality” of that action at that state.
A Q-table, a table where each cell corresponds to a state-action value pair value.
Q-Learning is the RL algorithm that:
- Trains Q-Function (an action-value function) which internally is a Q-table that contains all the state-action pair values.
- Given a state and action, our Q-Function will search into its Q-table the corresponding value.
- When the training is done, we have an optimal Q-function, which means we have optimal Q-Table.
- And if we have an optimal Q-function, we have an optimal policy since we know for each state what is the best action to take.
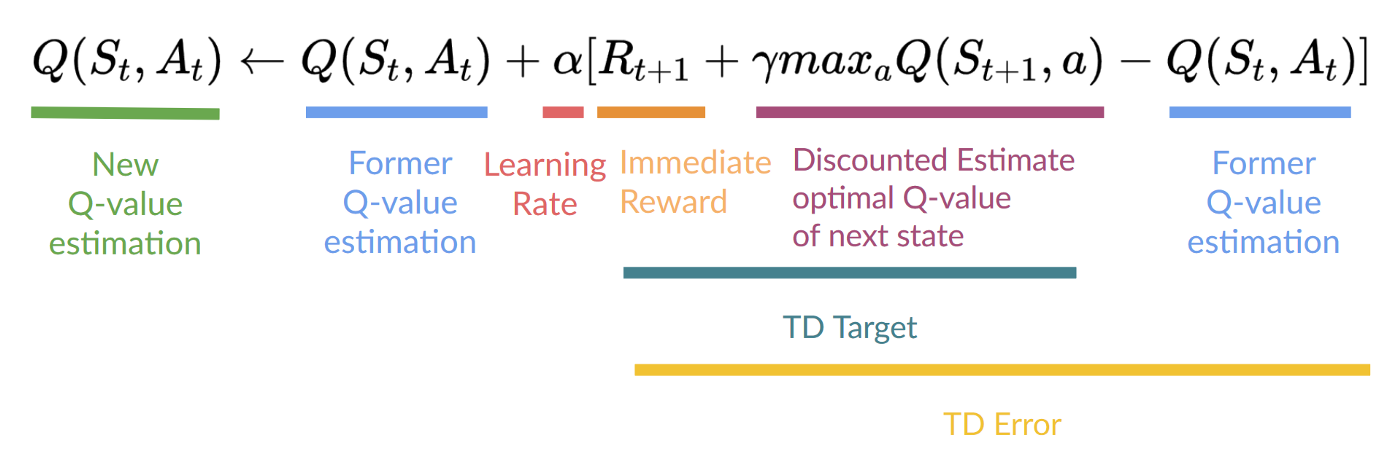
Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) after one step of the interaction.
To produce our TD target, we used the immediate reward Rt+1 plus the discounted value of the next state best state-action pair (we call that bootstrap).
It means that to update our Q(St,At)
- We need St,At,Rt+1,St+1.
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
- We obtain the reward after taking the action Rt+1.
- To get the best next-state-action pair value, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done. We start in a new_state and select our action using our epsilon-greedy policy again.
It’s why we say that this is an off-policy algorithm.


Comments