2 min to read
Reinforcement Learning Introduction

The idea behind Reinforcement Learning is that an agent (an AI) will learn from the environment by interacting with it (through trial and error) and receiving rewards (negative or positive) as feedback for performing actions.
Reinforcement Learning is just a computational approach of learning from action.
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback
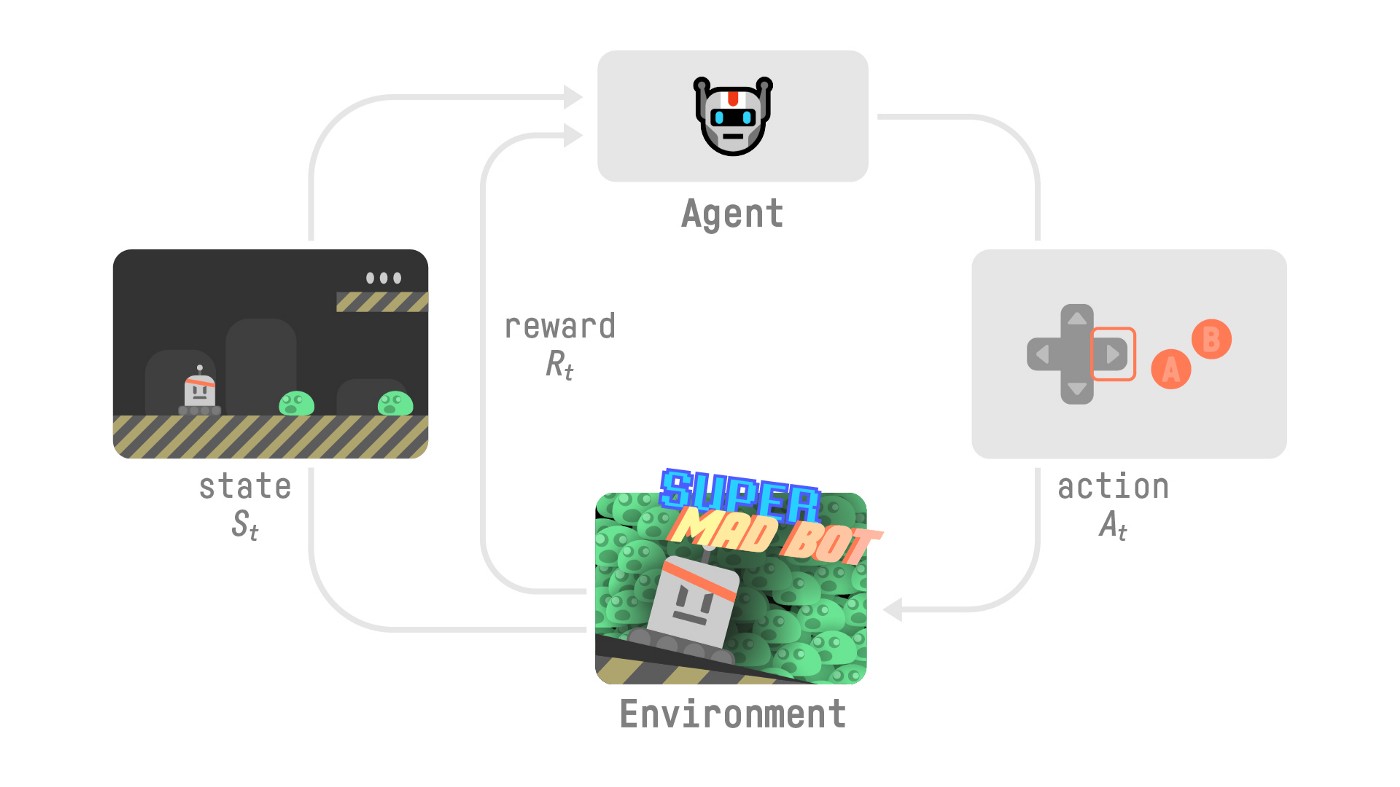
- Our Agent receives state from the Environment — we receive the first frame of our game (Environment).
- Based on that state , the Agent takes action — our Agent will move to the right.
- Environment goes to a new state — new frame.
- The environment gives some reward to the Agent — we’re not dead (Positive Reward +1).
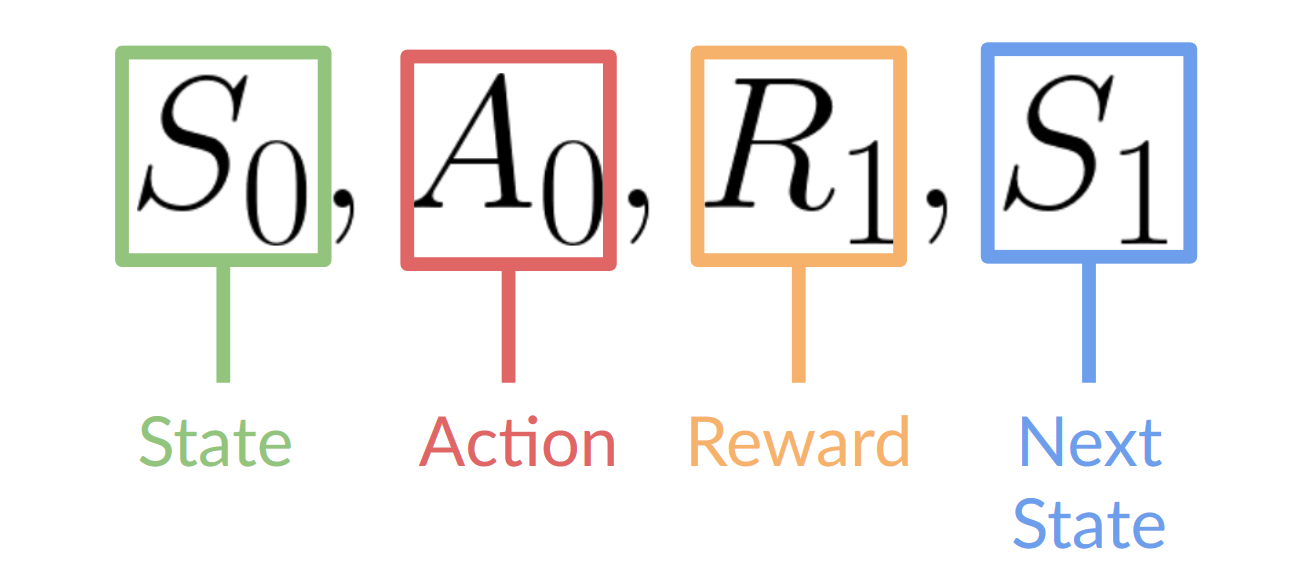
Because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected return (expected cumulative reward).
That’s why in Reinforcement Learning, to have the best behavior, we need to maximize the expected cumulative reward.
State s: is a complete description of the state of the world (there is no hidden information). In a fully observed environment.
Observation o: is a partial description of the state. In a partially observed environment.
States space are the information our agent gets from the environment
Action space is the set of all possible actions in an environment.
Reward is fundamental in RL because it’s the only feedback for the agent.
Thanks to it, our agent knows if the action taken was good or not.
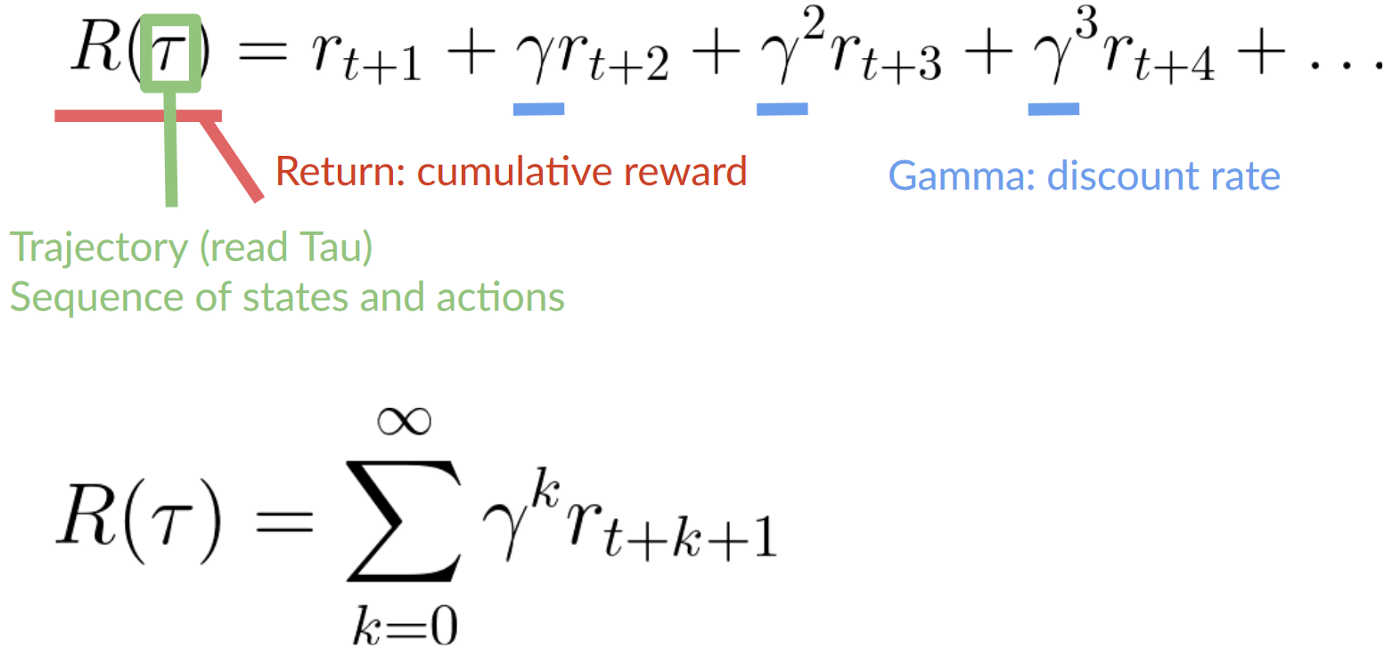
To discount the rewards, we proceed like this:
- We define a
discount ratecalledgamma. It must be between 0 and 1. Most of the time between 0.99 and 0.95.- The
largerthe gamma, the smaller the discount. This means our agent cares more about thelong-term reward. - On the other hand, the
smallerthe gamma, the bigger the discount. This means our agent cares more about theshort term reward(the nearest cheese).
- The
We need to balance how much we explore the environment and how much we exploit what we know about the environment.
- Exploration is exploring the environment by trying random actions in order to find
more information about the environment. - Exploitation is exploiting known
information to maximize the reward.
The Policy π is the brain of our Agent, it’s the function that tell us what action to take given the state we are. So it defines the agent’s behaviour at a given time.
This Policy is the function we want to learn, our goal is to find the **optimal policy** π, the policy that maximises expected return when the agent acts according to it. We find this π through training.*
There are two approaches to train our agent to find this optimal policy π*:
- Directly, by teaching the agent to learn which action to take, given the state is in:
Policy-Based Methods. - Indirectly, teach the agent to learn which state is more valuable and then take the action that leads to the more valuable states:
**Value-Based Methods**.


Comments