1 min to read
Reinforcement Learning : Deep Q Network
This is the architecture of our Deep Q-Learning network:
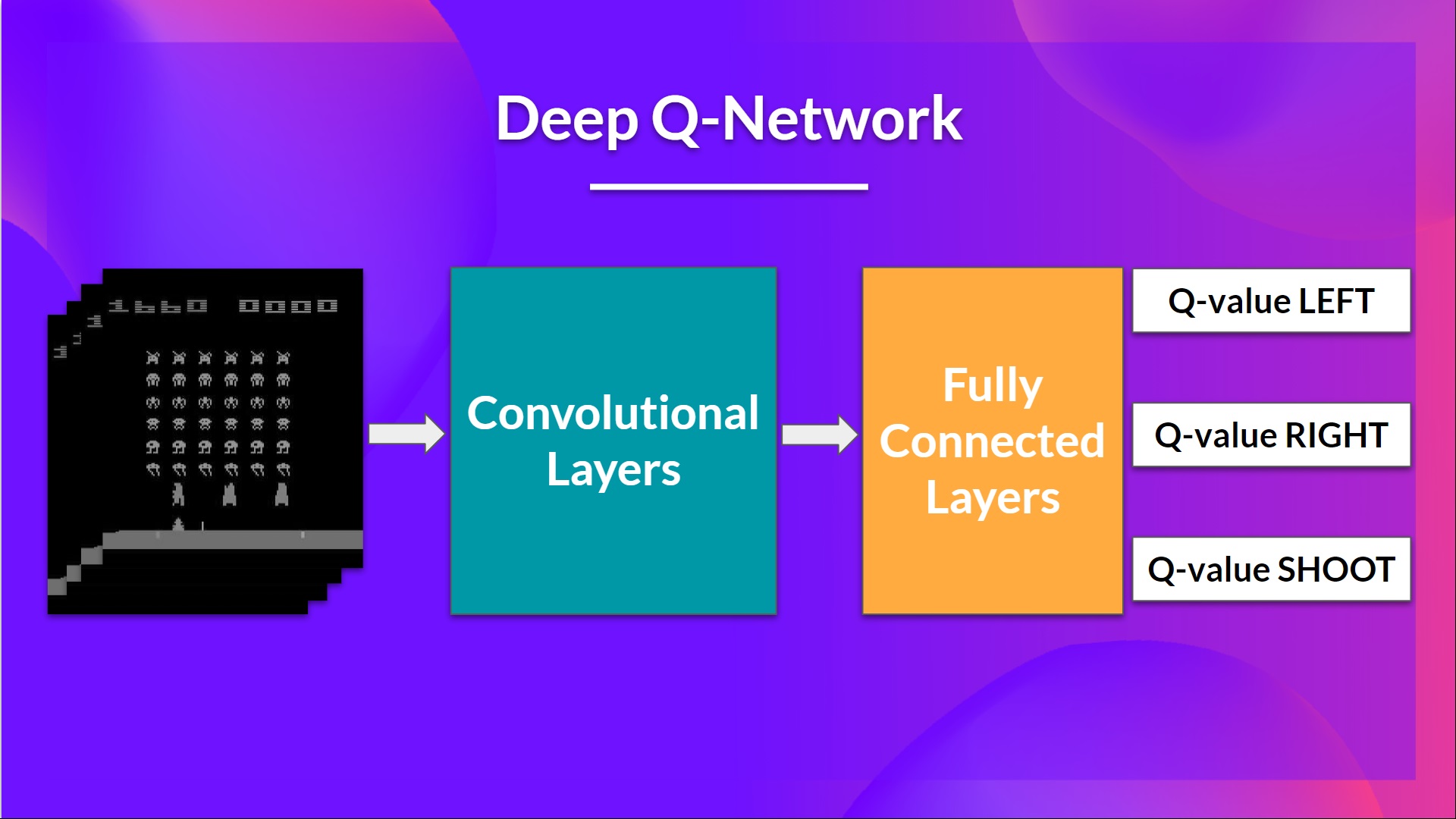
As input, we take a stack of 4 frames passed through the network as a state and output a vector of Q-values for each possible action at that state. Then, like with Q-Learning, we just need to use our epsilon-greedy policy to select which action to take.
When the Neural Network is initialized, the Q-value estimation is terrible. But during training, our Deep Q-Network agent will associate a situation with appropriate action and learn to play the game well.


Comments